TL;DR: Constituency Test (CT) is the de-facto linguistic method for unsupervised consituency parsing. We reconceptualize CT as a rejection sampling method and address CT’s high manpower cost problem: we use LLM to sample acceptable sentences instead of doing rejection sampling with human subjects.
The Challenge
Unsupervised constituency parsing, discovering syntactic structure without labeled data, remains a fundamental challenge in Computational Linguistics. Constituency Test (CT) is the standard linguistic method for unsupervised parsing, but it requires human parcipitation. Here, we ask can we scale up the CT for the benefit of unsupervised parsing?
Our answer is yes. We reconceptualize CT as “rejection sampling with human judgement”. This unlocks a new possibility: we can use more efficient sampling techniques.
Key Insight: Constituency Test as Rejection Sampling
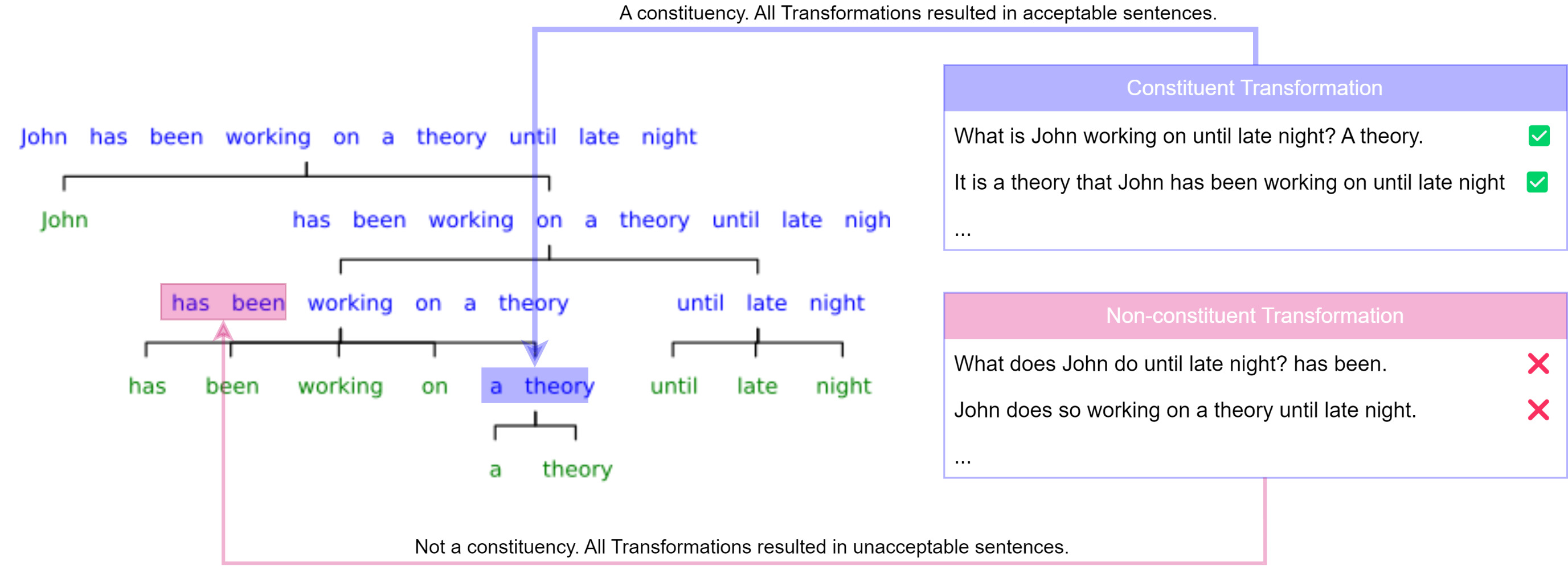
Constituency test works by
- Assuming a substring as constituent, generating a set of candidate sentences by applying pre-defined transformation to the candidate substring and the sentence.
- Asking human subjects to evaluate the generated sentences. If most sentences are acceptable, then the substring is considered constituent. If not, then it’s considered non-constituent.
- Repeat the process for all substrings.
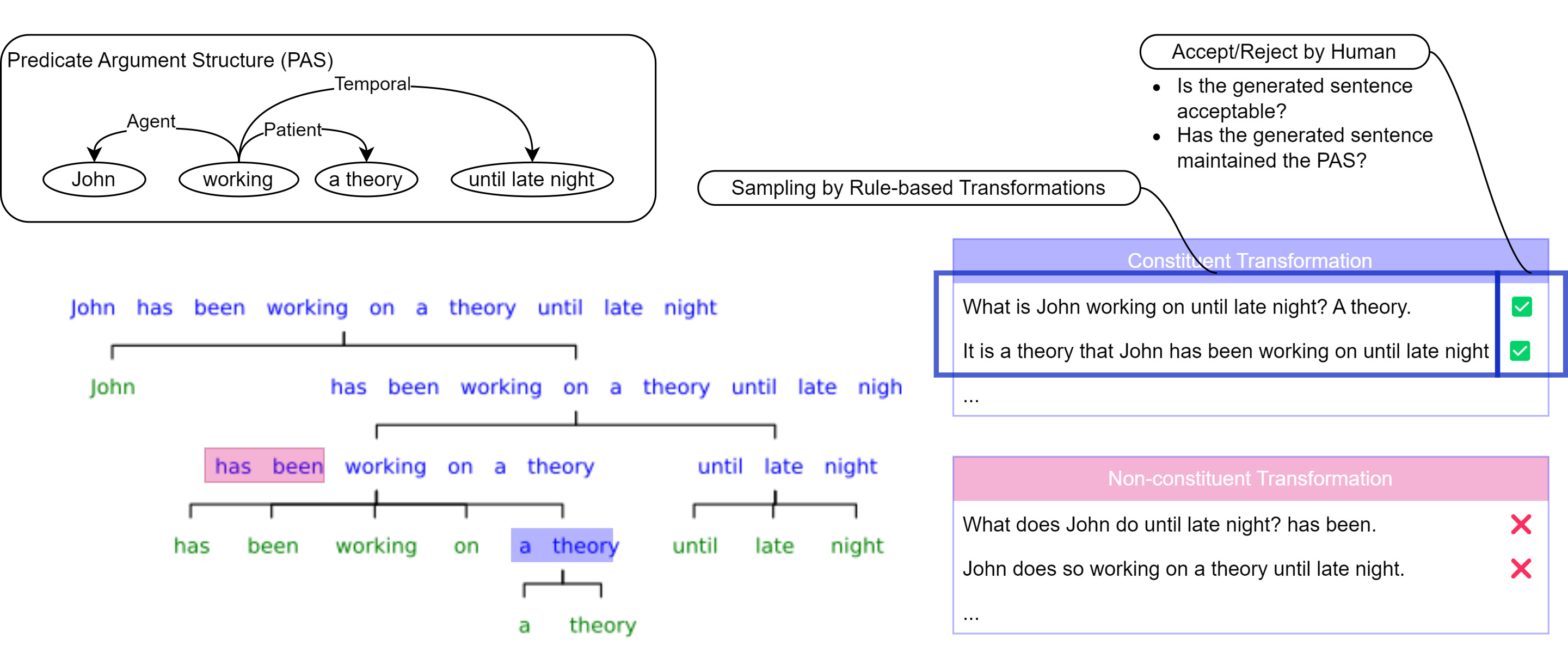
Step 1-2 closely resembles rejection sampling from natural langauge distribution conditioned on the Predicate-Argument Structure (PAS) [1].
- Step 1: Genearting sentences by applying predefined transformation to a substring ≈ Sampling from a proposal distribution conditioned on the candidate substring, the original sentence, and its semantics.
- (Expensive!) Step 2: Asking human subjects to evaluate the sample ≈ Accepting the proposed sample by 1. whether the sample is acceptable and 2. whether the sample maintains the semantics. This human involvement limits CT to small data scale upto hundreds of sentences.
[1] PAS is a semantic representation: it encodes natural language meaning by specifying the semantic role of entities.
Our Approach: Directly PAS-conditioned Sampling by LLM-based Paraphrasing
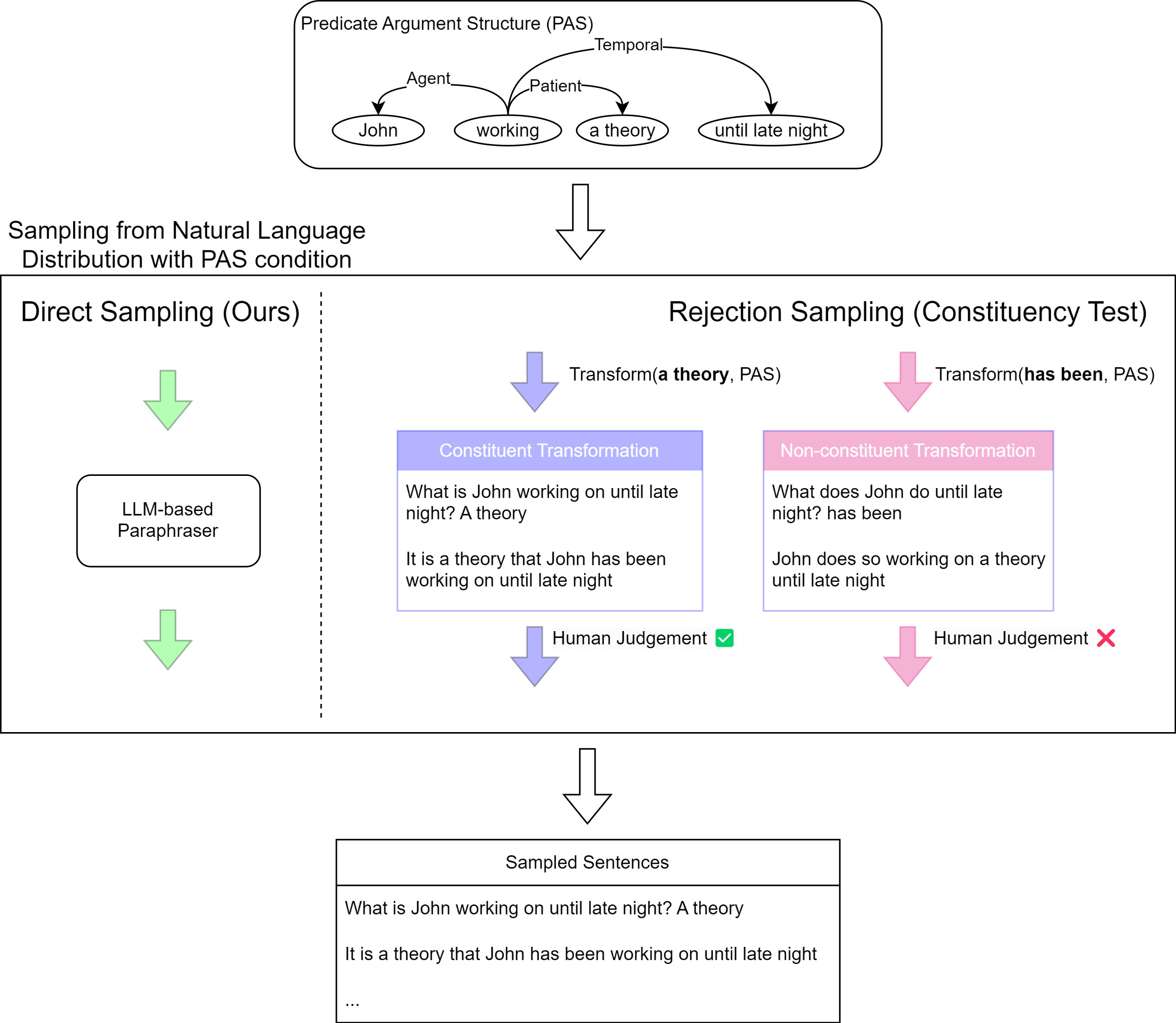
We address the manpower cost of CT: we adopt LLM-based paraphraser to replace human-involved rejection sampling. This replacement removes human factors from CT, scaling CT up to tens of thousands of sentences.
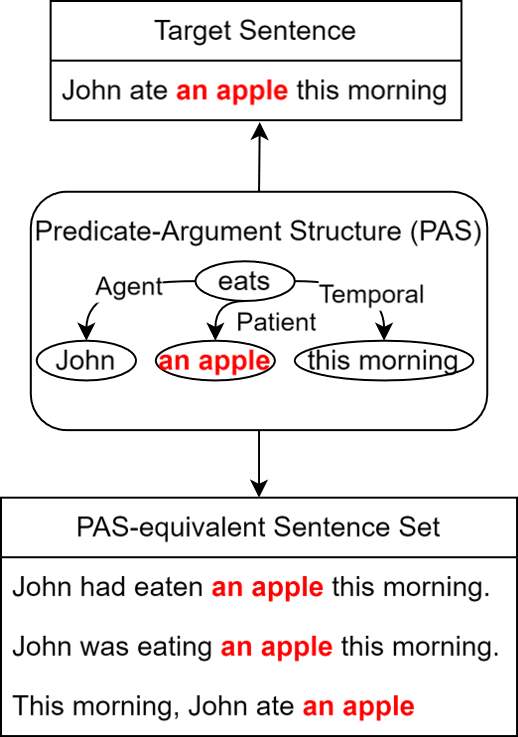
We can identify constituent substrings using substring frequency in LLM-generated paraphrases. As shown in the example, constituent substring tend to have high frequency, while non-constituent substring tend to have low frequency. This is because only constituent substrings result in acceptable and iso-semantic candidate sentences, which will survive the CT. Non-constituent substrings will only result in non-acceptable or hetero-semantic candidate sentences, which will not survive the CT and hence will not be included in the sentence samples.
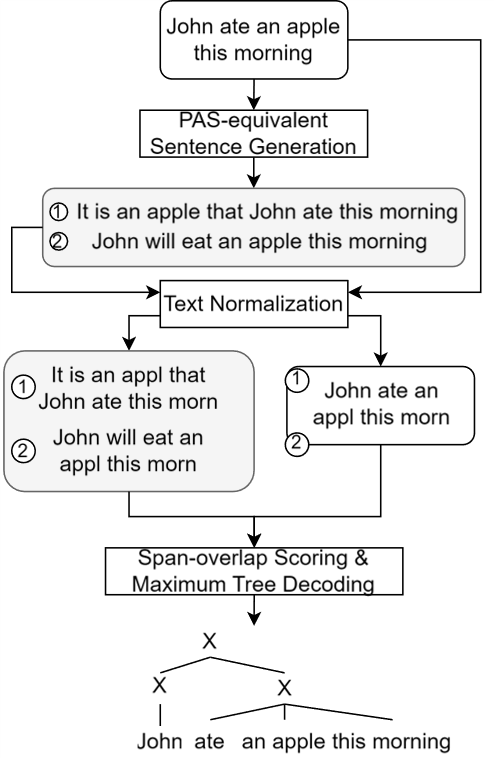
We propose the span-overlap method.
- Instruct GPT-3.5 to generating PAS-equivalent sentences in accordance with 6 predefined transformations
- Normalizing the original and the generated sentences
- Compute spanoverlap score (i.e., substring frequency among the PAS-equivalent sentences)
- Maximum tree decoding
Reference
@inproceedings{chen-etal-2024-unsupervised,
title = "Unsupervised Parsing by Searching for Frequent Word Sequences among Sentences with Equivalent Predicate-Argument Structures",
author = "Chen, Junjie and
He, Xiangheng and
Bollegala, Danushka and
Miyao, Yusuke",
editor = "Ku, Lun-Wei and
Martins, Andre and
Srikumar, Vivek",
booktitle = "Findings of the Association for Computational Linguistics: ACL 2024",
month = aug,
year = "2024",
address = "Bangkok, Thailand",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.findings-acl.225/",
doi = "10.18653/v1/2024.findings-acl.225",
pages = "3760--3772",
abstract = "Unsupervised constituency parsing focuses on identifying word sequences that form a syntactic unit (i.e., constituents) in target sentences. Linguists identify the constituent by evaluating a set of Predicate-Argument Structure (PAS) equivalent sentences where we find the constituent appears more frequently than non-constituents (i.e., the constituent corresponds to a frequent word sequence within the sentence set). However, such frequency information is unavailable in previous parsing methods that identify the constituent by observing sentences with diverse PAS. In this study, we empirically show that constituents correspond to frequent word sequences in the PAS-equivalent sentence set. We propose a frequency-based parser, span-overlap, that (1) computes the span-overlap score as the word sequence{'}s frequency in the PAS-equivalent sentence set and (2) identifies the constituent structure by finding a constituent tree with the maximum span-overlap score. The parser achieves state-of-the-art level parsing accuracy, outperforming existing unsupervised parsers in eight out of ten languages. Additionally, we discover a multilingual phenomenon: participant-denoting constituents tend to have higher span-overlap scores than equal-length event-denoting constituents, meaning that the former tend to appear more frequently in the PAS-equivalent sentence set than the latter. The phenomenon indicates a statistical difference between the two constituent types, laying the foundation for future labeled unsupervised parsing research."
}