TL;DR: Constituent structures encode fine-grained semantics as constituent substrings, which can be identified as high-information substrings among paraphrases.
The Challenge
Unsupervised constituency parsing, discovering syntactic structure without labeled data, remains a fundamental challenge in Computational Linguistics. While recent approaches rely heavily on language modeling objectives, we ask: Is language modeling alone sufficient for accurate parsing?
Our answer is no. We propose that sentence-level semantic information provides crucial signals for robust parsing that pure distributional methods miss.
Key Insight: Syntax Encodes Semantics
Constituent Structure as Semantic Representation
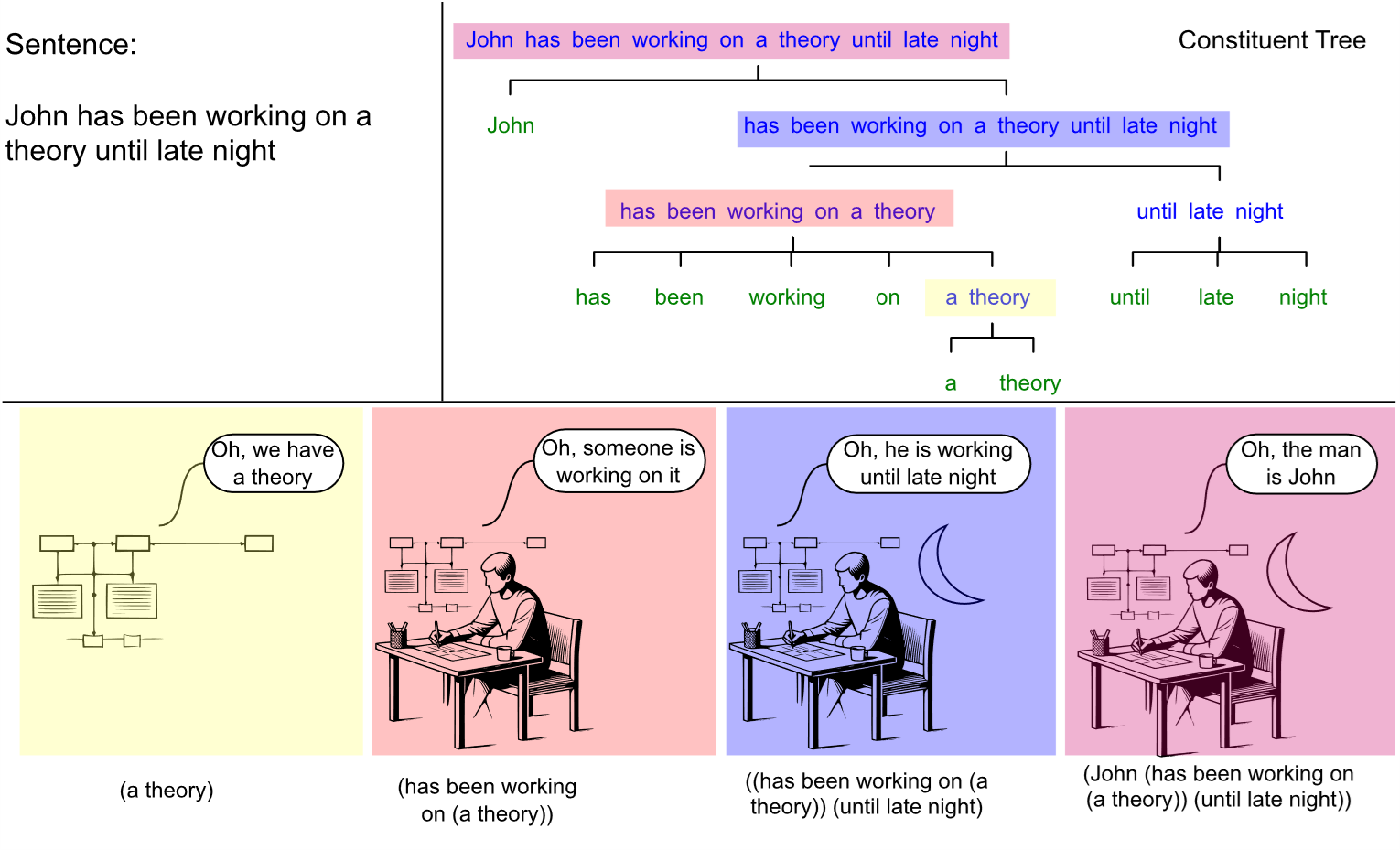
Each node in a constituent tree corresponds to a meaningful semantic unit. This one-to-one correspondence between syntactic constituents and partial meanings suggests we can invert the problem: identify constituents by finding semantically coherent substrings.
Our Approach
Step 1: Quantifying Semantic Information via Paraphrasing
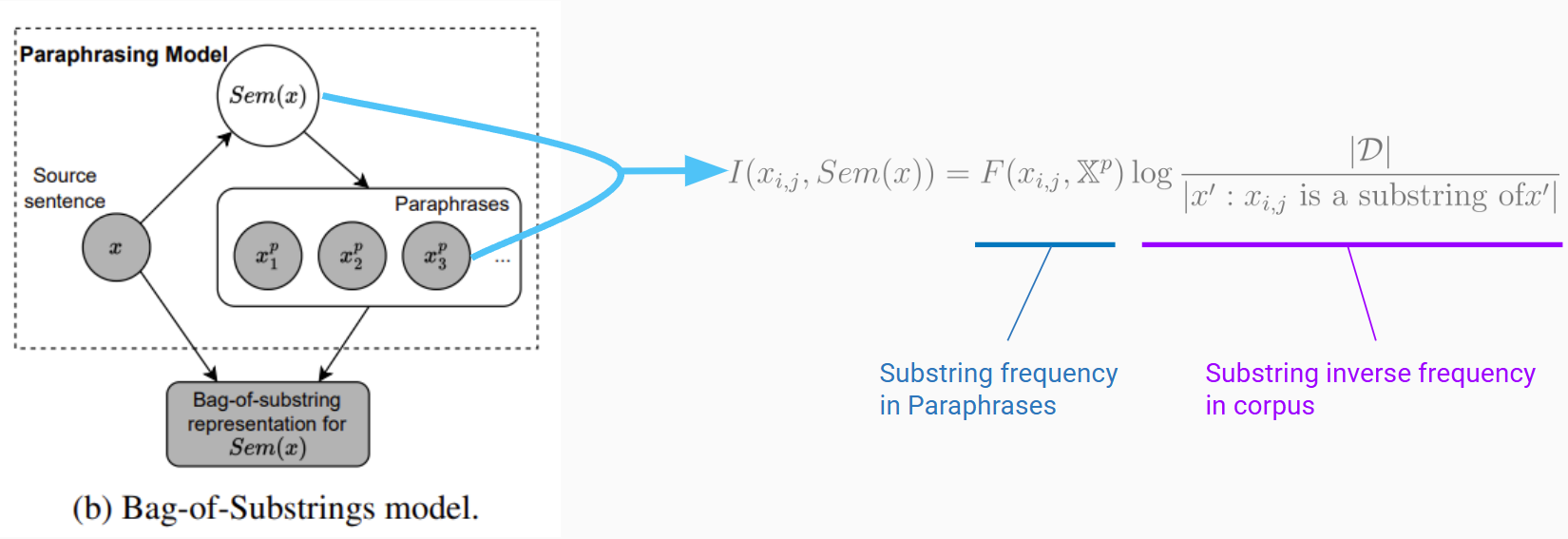
We leverage paraphrases to identify semantically important substrings. The intuition: constituents should appear consistently across paraphrases of the same sentence, while arbitrary substrings should not.
Step 2: Why Traditional Methods Fall Short
We compared two approaches for estimating substring semantic information:
Neural Similarity (Bge-M3)

Neural embeddings struggle to distinguish between constituent (blue) and random substrings (red), showing nearly identical scores.
Our TF-IDF Approach

By treating substrings “generated” by semantics in paraphrasing sentences (identical to how words are “generated” by topics in documents), TF-IDF naturally captures the substring-semantics interactions (as measured by semantic information).
Step 3: Learning to Parse via Information Maximization
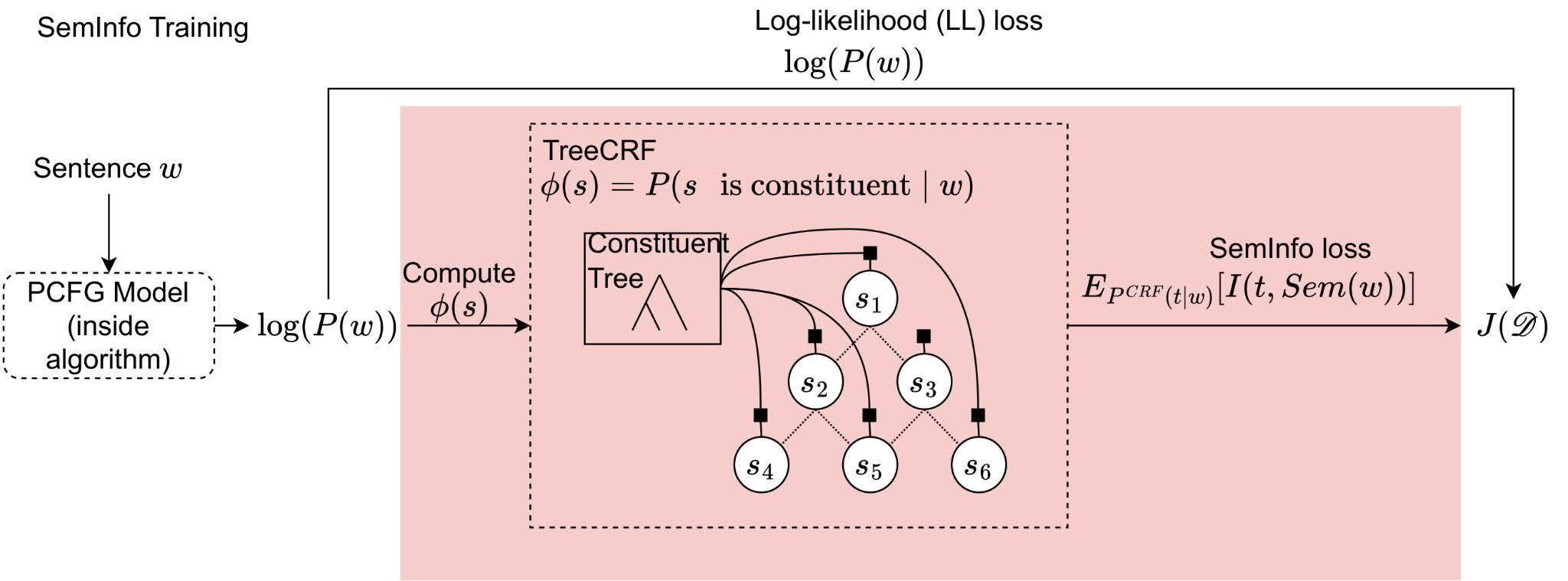
We use reinforcement learning to train a parser that maximizes the semantic information of predicted constituents. This bridges semantic objectives with traditional syntactic parsing through a unified optimization framework.